The A/B Test That Built the Lathe
I pasted a two-paragraph plan into a terminal and walked away for two days. The strategy package that came back was good. Then I asked Claude to do it again from a template, without me in the feedback loop. The template version landed at 70-80% of the quality in 10-15x less time. The gap — and the loop that closed it — has a name from another century.
Nino Chavez
Product Architect at commerce.com
This post has been challenged
by Self Red Team
On March 13 I pasted a two-paragraph plan into a terminal. The plan said: build the strategy package for a pricing-and-packaging initiative — leadership documents and an agentic billing-support prototype. Then I walked away.
Two days later there was a deployed prototype with eleven pages, four strategy documents validated against the production codebase, cross-industry research covering fourteen platforms with thirty-plus cited sources, and a design system extracted from screenshots of the existing product. I hadn’t written a line of code or a word of doc copy. Every artifact was the agent, steered by feedback.
The interesting part wasn’t what got built. It was the question I asked at hour eighteen: can this happen again, for a different initiative, without me in the feedback loop?
What I did to answer that question — and what came out of it — is the thing the post is actually about.
What got built in those two days
Most of the first eighteen hours wasn’t generation — it was correction. The agent got the voice wrong (defaulted to external consultant, not internal team). It invented UI components that didn’t exist in the actual product. It used words that created merchant anxiety (“surcharge,” “non-preferred,” “BLOCKED”) — a hundred-plus replacements across sixteen files. It made claims that didn’t survive a check against the production codebase. Every one of these was caught by a single human reading the output and asking is this right?
What the agent could not do alone was the part where the work earned the right to be taken seriously — the research spikes I added on instinct (“would it help to look at utility billing? what about Comcast and AT&T?”), the design references I dropped in by uploading forty-two screenshots from my own SaaS bills, the credibility check that asked the agent to validate its own claims against actual screenshots and source code. Call that the twenty-five to thirty percent of quality that comes from the human noticing something the agent wouldn’t have noticed on its own.
Everything else — the eleven prototype pages, the four documents, the cited sources, the extracted design system — was the agent, executing prompts, refining against feedback. The production line above it already existed: specchain converts intent into a spec and a task list. forge-brand emits a typed design system. forge-signal writes the prose. gen-images renders the visuals. Each tool consumes the previous tool’s output as input.
At hour eighteen the work was effectively done. That’s when I asked whether it could happen again from a template.
The extraction
big-blueprint came out of those eighteen hours by asking the agent to extract the methodology into a reusable jig. A template directory. Five skills for the pipeline stages. Four agent definitions (researcher, prototype-builder, doc-writer, validator). A configuration file with execution depth, voice modes, and research scope. Composable with specchain and forge-signal.
The extraction wasn’t the test. The test was: start a new project from this template, point it at the same kind of input, give it none of my feedback, and see what comes out.
| Deliverable | Produced by | Solo version |
|---|---|---|
| Strategy documents | forge-signal after voice fix | Weeks of analyst drafting |
| Cross-industry research with citations | Research spikes + the agent’s web tools | Weeks of analyst time |
| Design system extracted from screenshots | Extraction prompt against existing product | Design audit + manual tokenization |
The chassis (big-blueprint itself) | Extracted from the run while it was running | Would not have been built |
The last row is the one that matters. Every other row scales linearly with effort. The last row scales because the methodology that just shipped the work was now a starting point for the next initiative, not something to reinvent.
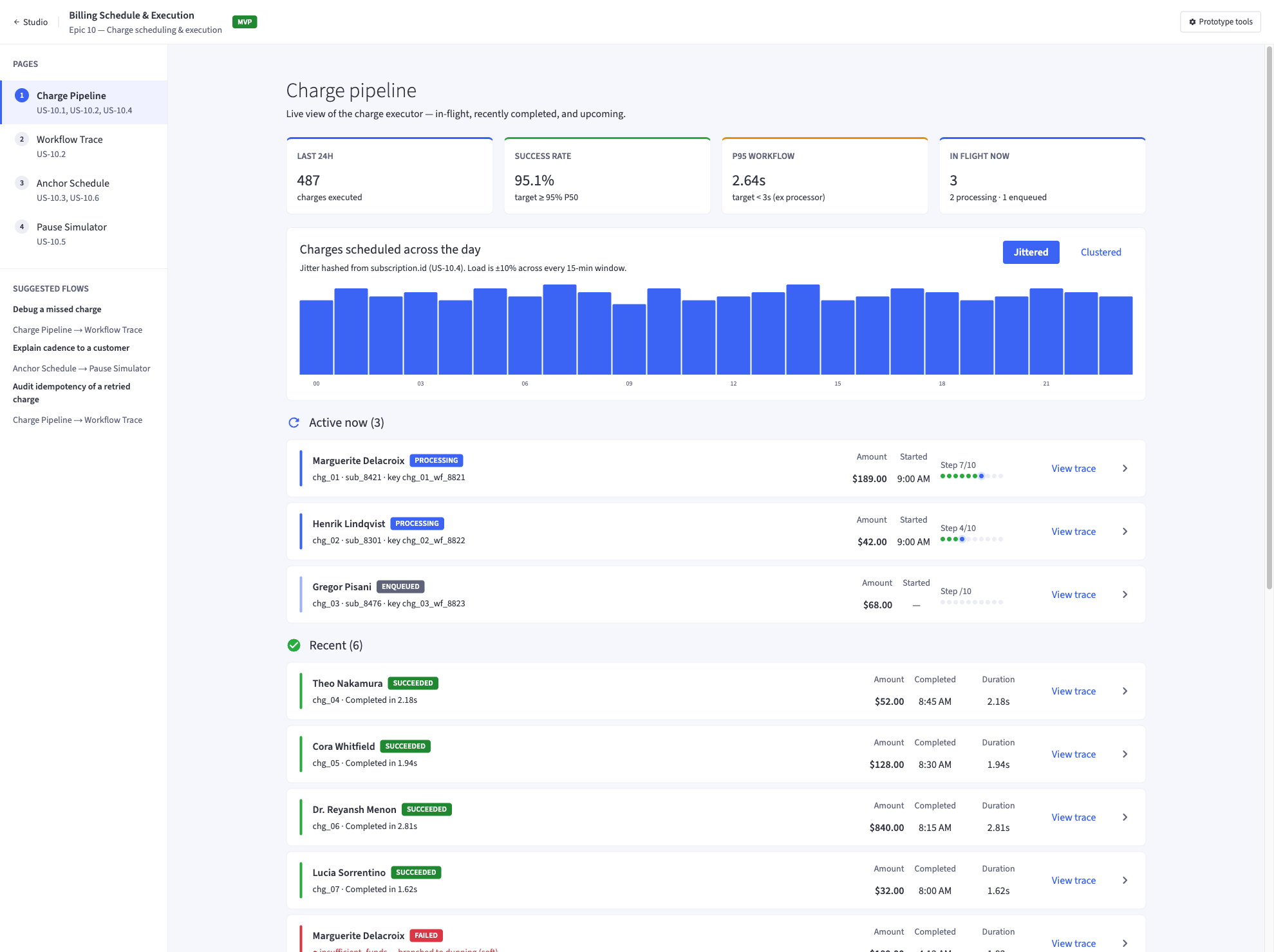
That diagram is from a different initiative — a subscriptions prototype that came after the first run. I show it because it is the same chain, demonstrably reused. The fact that I can show it here as evidence is the evidence.
The A/B test
The template version ran with no feedback from me. The first pass came back at 70-80% of the quality, in 10-15x less time.
The 70-80% mattered more than the 10-15x. The shortfall was specific and itemizable. The agent used the placeholder terminology from the template instead of the actual product’s terms (“deflectable” instead of “resolvable without support”). It didn’t flag a methodology gap the original run had caught. It cited research sources by name but not by URL. None of those were generation failures. They were template gaps — places where the original run had inputs the template didn’t carry forward.
Six fixes went into the template:
- A populated terminology table, so the next run wouldn’t substitute placeholder vocabulary
- A citation-URL requirement, so sources had to resolve
- A methodology-questioning step in the quality audit
- A skeleton index page so the doc pipeline didn’t block on a missing file
.gitkeepfiles for empty directories the agent kept tripping over- A
docs/package.jsonthat had been silently breaking the doc build
The re-test passed all six checks. The agent used correct terminology on the first draft, flagged the methodology contradiction the first test missed, cited nineteen URLs, and spontaneously self-reviewed against the banned-words list.
The lathe didn’t get sharper because the agent got smarter. It got sharper because the artifacts the agent reads got more precise.
Then it kept running
On May 1 — forty-nine days after the A/B test — I caught a drift. A subscriptions prototype I was building against a commerce platform had evolved a working harness inside its own repo. The big-blueprint template upstream of it had not. The two were diverging.
The obvious move was to backport: pull the working pieces back into the template. I didn’t do that. After walking through the options I approved a different path — ship the slice shape as a real prototypes/_template/ directory and have the agent clone it with cp -r for every new slice, instead of regenerating the shape from a prose description. Same concept as the first A/B test. The artifact is the spec; a mechanical copy can’t drift the way generation does.
Then big-blueprint ran against rally-hq — a volleyball tournament platform, a different domain. The pattern held. Where it didn’t, the gaps got named, and the template absorbed the fix.
Then it ran against ninochavez.co — a personal site, a totally different reason for existing. Same outcome.
Each application improved the lathe. The version of big-blueprint that now sits in front of the next prototype is not the version that came out of the March extraction. It’s been polished by passes against projects it wasn’t originally designed for, which is exactly the friction that makes a chassis generic enough to be worth keeping.
That feedback cycle is the part most “AI productivity” stories skip. They tell the story of how the tool worked the first time. The harder question is what happens the third time and the fourth, when the tool is being used by the version of you that has already been changed by using it.
The lathe, not the engine
The Industrial Revolution gets remembered as steam. That’s the wrong inflection. The actual inflection was Maudslay’s screw-cutting lathe — a machine that produced precise, identical, interchangeable parts that other machines could be built from. Whitney, Roberts, Nasmyth, Whitworth: they did not invent better goods. They invented the tools that made the goods possible.
Steam was the power source. The lathe was the multiplier.
The LLM is the steam engine of this moment. It is genuinely new power. But power doesn’t compound on its own. Code generation alone produces more code, faster, the same way more steam produced more spindles spinning faster — and produced piles of yarn that no downstream loom could weave because the yarn wasn’t standardized.
The chassis is the lathe. The template directory. The spec format. The brand bridge. The contract that says every prototype slice exposes the same shape, so the next thing built on top can assume it. These are the boring infrastructure pieces that turn raw generative output into something the next layer can consume without rewriting. They work the way Whitworth’s slip gauges worked: not as written tolerances a worker has to interpret, but as physical objects that either fit or don’t. The artifact is the standard.
The March A/B test was me building the lathe. The May 1 backport-that-wasn’t was me noticing the lathe needed updating. Not the goods. Not even the recipe. The lathe.
What’s about to get confused
The conflation I expect to see — and that I think most of the industry is already making — is treating the LLM as the inflection point and skipping the chassis work.
It looks like this in practice — and the mechanism here is the one Adam Bender names in his recent Google I/O talk. A team gets agents producing code at 10x. They ship faster. The dependency graph quietly grows quadratically. The internal APIs drift. Code review becomes the bottleneck. The team adds more agents to do the review, which produces more drift. Six months later they have a codebase no human can hold in their head and no agent can refactor without breaking, and they conclude the agents didn’t work.
The agents worked. The chassis didn’t exist.
The work that compounds, right now, is not prompt engineering and it is not even building agents. It is building the lathes — the templates, schemas, contracts, validators, archetypes — that let the next generation of agent output be structurally sound by default, instead of being carefully reviewed into soundness one PR at a time.
A whitepaper version of the production line, with the actual contracts and both case studies — the pricing-and-packaging initiative that hatched the tool and the subscriptions prototype that exercised it — is coming. This post is the why. That one will be the how.
The pattern has now survived contact with four projects — a pricing-and-packaging initiative, a subscriptions prototype, a tournament app, and a personal site — with the tool itself getting sharper at every pass. Each project surfaced something the prior project missed. What I don’t know yet is whether the cycle survives contact with a team — whether the lathe holds its shape when other people are also turning the crank. But the shape of the bet is clear enough to name: the engineers who win the next cycle are the ones who notice they’re being asked to do lathe work and accept the assignment.